When fine-tuning VLA models, a continuous action loss is applied uniformly over the whole trajectory.
Yet manipulation failures are not uniform—they tend to concentrate around gripper-state transitions,
appearing either as a motion-fail (failing to reach and grasp during free-space motion) or a
skill-fail (grasping successfully but erring during post-grasp execution such as handover, stacking, or rotation).

Figure 1: Manipulation failures concentrate around gripper-state transitions. A
motion-fail occurs when the robot fails to reach and grasp the target during free-space motion,
while a skill-fail occurs when the robot grasps successfully but fails during post-grasp skill execution.
A manipulation trajectory is not homogeneous: it alternates between free-space motion and
contact-constrained skill execution, with gripper open/close events marking the boundaries.
StaKe injects this structure into VLA fine-tuning through two auxiliary signals derived
automatically from demonstration gripper states—requiring no manual annotation and no change to inference:
-
Stage Supervision (SS): a lightweight head classifies each timestep into the
motion or skill stage, encouraging the backbone to encode stage-aware representations.
-
Keyframe Supervision (KS): a second head predicts the joint action at the next
gripper-transition keyframe, anchoring the policy to physically meaningful transition targets.
Both signals are implemented as auxiliary heads attached to dedicated learnable query tokens, jointly
optimized with the flow-matching policy loss during training. At inference, the auxiliary heads are not
invoked, so the base policy and its inference loop remain entirely unchanged.
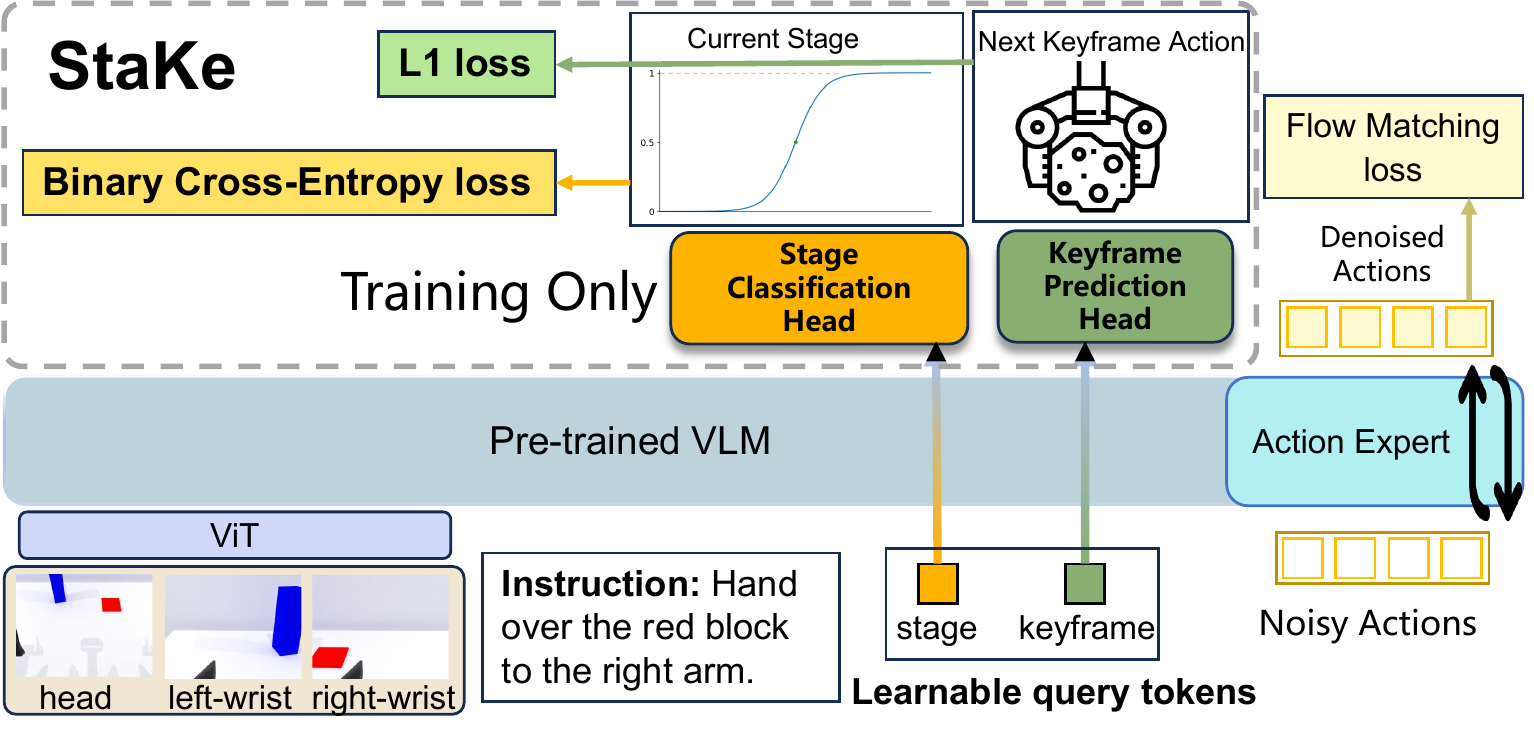
Figure 2: Overview of the StaKe framework. Two learnable query tokens are appended to the
pre-trained VLM backbone, each feeding a lightweight auxiliary head: a stage classification head (binary
cross-entropy loss) and a keyframe prediction head (L1 loss). Both heads are active only during training and
jointly optimized with the flow-matching policy loss; at inference the query tokens remain but the heads are not invoked.